原理 众所周知,任何数据在内存中都是以Byte为单位进行存储的,每个Byte包含了8个二进制位,因此本文不区分二进制数据与文本,而是将其作为一个整体进行讨论。
编码 base64编码包括以下几个步骤
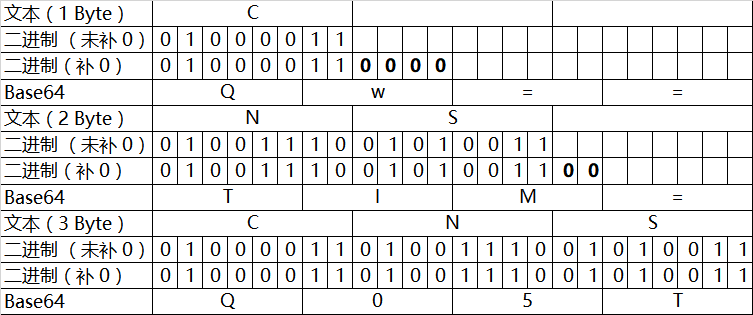
将每个BYTE转为8位二进制
若二进制位不是6的倍数则在其后面补0直到其变为6的倍数
将每6个二进制位作为整体转换为10进制
通过查表将十进制转为字符
若转出的长度不为4的倍数,则在其后补’=’
注: 转换表见附录
若是以编码 CNSS 为例,则整个过程为
解码 base64解码包括以下几个步骤
将除了 = 以外的别的字符通过查表转为十进制数字
将十进制数字转为6位二进制
删去等号个数*2位二进制 将二进制转为BYTE
黑魔法:base64隐写 由上面的过程可以看出,在编码的过程中补上了一些0,若是补充的不是0,而是一些有意义的数据,那么就可以在不改变解码结果的情况下,添加额外的数据
脚本 下面为python3的脚本,包括生成隐写,解隐写
目前已加入ctf大礼包 : ctf大礼包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import base64def get_base64_diff_value (s1, s2 ): """get base64 diff value""" base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' for i in range (len (s2)): if s1[i] != s2[i]: return abs (base64chars.index(s1[i]) - base64chars.index(s2[i])) return 0 def solve_stego (stego_str_list ): '''stego_str_list str列表''' bin_str = '' for stego_str in stego_str_list: stego_str = stego_str.replace('\n' , '' ) norm_str = base64.b64encode(base64.b64decode(stego_str)).decode() diff = get_base64_diff_value(stego_str, norm_str) pads_num = stego_str.count('=' ) bin_str += bin (diff)[2 :].zfill(pads_num * 2 ) ret = b'' for i in range (0 , len (bin_str), 8 ): ret += int (bin_str[i:i + 8 ], 2 ).to_bytes(1 , 'little' ) return ret def to_stego (normal_data, stego_data, stego_bit_len=4 ): base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' bin_str = '' for each in stego_data: bin_str += bin (each)[2 :].zfill(8 ) line_len = len (normal_data) // (len (bin_str) // stego_bit_len) if stego_bit_len == 4 : line_len = line_len - ((line_len % 3 - 1 ) + 3 ) % 3 else : line_len = line_len - ((line_len % 3 - 2 ) + 3 ) % 3 if line_len <= 0 : return [] ret = [] index = 0 while True : if index >= len (normal_data): break encode_str = base64.b64encode(normal_data[index:index + line_len]).decode() index += line_len if bin_str != '' : if stego_bit_len == 4 : now_encode = bin_str[:4 ] bin_str = bin_str[4 :] tmp_list = encode_str.rpartition(encode_str[-1 * (stego_bit_len // 2 + 1 )]) encode_str = tmp_list[0 ] + base64chars[base64chars.index(tmp_list[1 ]) + int (now_encode, 2 )] + tmp_list[2 ] ret.append(encode_str) return ret def main (): with open ('2.txt' , 'rb' ) as fp: file_lines = fp.readlines() stego_str_list = [] for each in file_lines: stego_str_list.append(each.decode().replace('\n' , '' )) print (solve_stego(stego_str_list)) l = to_stego(b'123456789012345678901234567890123456' , b'cnss' , 4 ) print (l) print (solve_stego(l)) if __name__ == '__main__' : main()
附录 转换表 转换表分为几种形式
表格 转换表:
索引
对应字符
索引
对应字符
索引
对应字符
索引
对应字符
0
A
17
R
34
i
51
z
1
B
18
S
35
j
52
0
2
C
19
T
36
k
53
1
3
D
20
U
37
l
54
2
4
E
21
V
38
m
55
3
5
F
22
W
39
n
56
4
6
G
23
X
40
o
57
5
7
H
24
Y
41
p
58
6
8
I
25
Z
42
q
59
7
9
J
26
a
43
r
60
8
10
K
27
b
44
s
61
9
11
L
28
c
45
t
62
+
12
M
29
d
46
u
63
/
13
N
30
e
47
v
14
O
31
f
48
w
15
P
32
g
49
x
16
Q
33
h
50
y
文本 以下为python语法
1 table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
引用 本文参考自
百度百科 : base64
推酷 : ZJPCCTF:我未见过的base64隐写
附件 base64编码过程表: base64.xlsx